
The Support Team That Doesn't Sleep
Agents are working no matter what the time, or day it may be. Is that a good thing?

Everyone celebrated when deflection rates hit 40%.
Then 50%. Then 60%.
The dashboards looked great. Leadership was happy. The QBR slides wrote themselves. Every percentage point was proof that the AI investment was paying off.
Nobody stopped to ask what happens at 80%.
Here’s something the industry isn’t talking about yet, but will be soon.
When AI deflects the majority of your ticket volume, your human agents stop seeing the full spectrum of customer problems. They stop encountering the edge cases. They stop building pattern recognition against a wide, varied dataset of human behavior and frustration and need.
What’s left in the human queue gets progressively harder, stranger, and more emotionally charged — because the AI successfully skimmed off everything manageable.
You’ve optimized your way into a skills gap.
And the worst part? It’s invisible. Your metrics look fine. CSAT is holding. Handle time is down. You won’t see the damage until the day something goes catastrophically wrong — a widespread outage, a billing crisis, a PR incident — and you suddenly need your team to perform at the highest level they’ve ever been asked to perform.
That’s the day you find out whether you kept them sharp.
I’ve been thinking about this a lot since we started leaning hard into AI-assisted resolution.
The deflection wins are real. I’m not going to pretend otherwise. When AI handles a “how do I reset my password” or “where is my invoice” at 2am without a single human touching it, that’s a genuine win — for the customer, for the agent, for the operation.
But there’s a version of that win that becomes a trap.
The trap is when you stop treating deflection as a tool and start treating it as the goal. When the KPI becomes the strategy. When the number on the slide becomes the north star.
Because what you’re really doing when you deflect a ticket is making a bet. You’re betting that the AI handled it completely, correctly, and in a way that left the customer satisfied. Sometimes that bet pays off. Sometimes the customer replies to the AI-generated resolution two days later, more frustrated than when they started, and now they’re in a human queue carrying that frustration.
That’s not a deflection. That’s a delayed escalation. And delayed escalations are harder to resolve.
There’s a concept in aviation called “automation complacency.” It’s what happens when pilots rely so heavily on autopilot systems that their manual flying skills degrade. The plane is performing beautifully. The instruments are nominal. Everything is fine.
Until it isn’t.
And then the humans in the cockpit, the ones who were supposed to be the failsafe, are rusty. Slow to react. Under-practiced for the moment that actually required them.
I think about that every time someone in CX celebrates a deflection milestone without asking the follow-up question.
What are your agents practicing?
If 80% of the volume is being resolved before it reaches a human, your team is training on 20% of the data. The 20% that was too complex, too emotional, or too unusual for the AI to handle. The 20% that, by definition, does not represent the full range of what customers need from your brand.
That’s a narrow training set for the people you’re depending on when it matters most
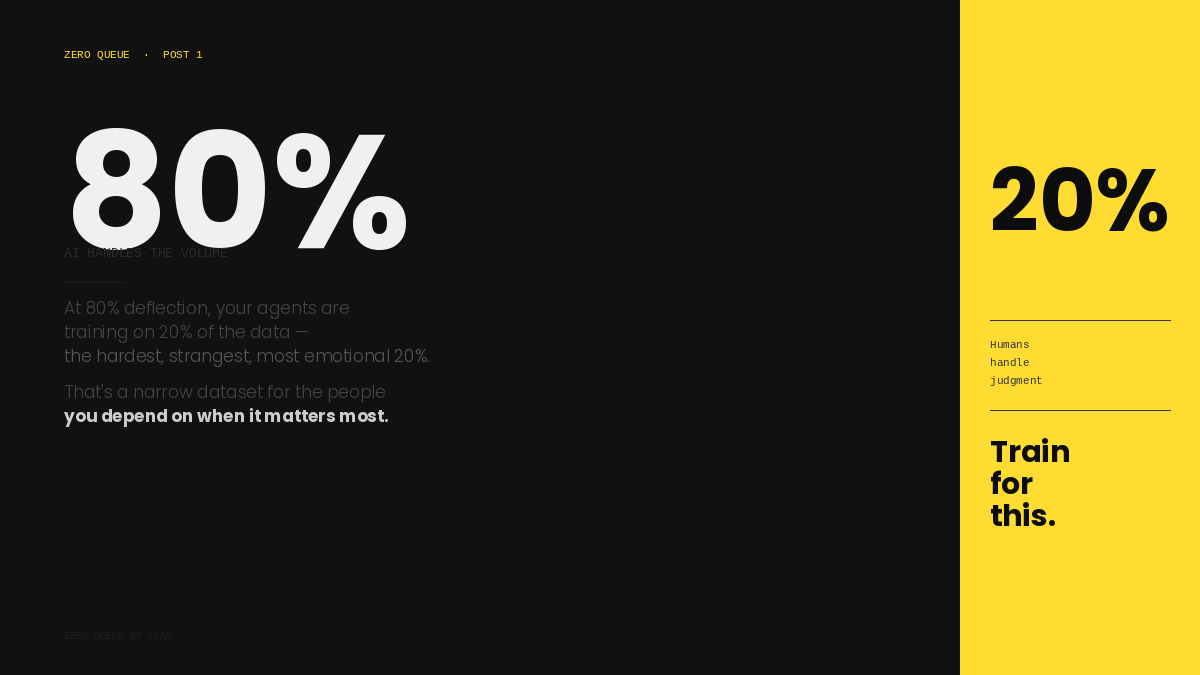
.
The handoff is everything.
This is something I’ve come to believe deeply. The real test of an AI-assisted support operation isn’t how much the AI deflects. It’s what happens in the moments where the AI recognizes its own limit and passes the conversation to a human.
That transition — from automated to human — is one of the highest-stakes moments in the entire customer journey. The customer has already been talking to a bot. They’ve already tried the self-service path. They’re coming into the human conversation with a specific emotional signature: somewhere between frustrated and cautiously hopeful.
If your agent fumbles that handoff — if they don’t have full context, if they ask the customer to repeat themselves, if they take too long to understand the situation and respond with something useful — you haven’t just failed to resolve a ticket. You’ve confirmed the customer’s worst fear about AI-powered support: that it’s just a wall between them and real help.
The handoff is where the brand either earns trust or loses it.
And right now, most teams are under-investing in it. They’re spending their time on deflection rate, on AI configuration, on prompt tuning and bot flows. Very little time is being spent on what happens in the 7 seconds after a bot says “let me connect you with a specialist.”
So what does it look like to actually train for the 20%?
It means building simulations around the scenarios your AI can’t handle — the emotional escalations, the edge case billing disputes, the situations that require genuine judgment and empathy and a little bit of creative problem-solving.
It means reviewing handoff transcripts the same way you review any other quality interaction. Looking not just at resolution, but at the transition itself. Did the agent acknowledge the AI interaction? Did they pick up the context without friction? Did the customer feel seen in the first 60 seconds?
It means rethinking what “agent development” means in an AI-augmented environment. Because if your agents are only seeing hard tickets, their training needs to reflect that. You can’t continue running coaching programs built for the full-spectrum queue when the full spectrum has been automated away.
It means being honest about what your AI actually does when it fails. Not the edge cases you know about. The quiet failures — the resolutions that technically closed a ticket but left a customer who never came back.

The support teams that will define the next five years of CX aren’t the ones with the highest deflection rates.
They’re the ones that figured out how to build humans and AI into a system that’s better than either one alone. Where the AI handles scale and the humans handle judgment. Where handoffs are seamless and agents are sharp. Where the 20% is treated with as much operational intention as the 80%.
The AI never gets tired. It never has a bad day. It never clocks out.
That’s exactly why the people on your team need to be extraordinary.
Train for the 20%. Because that’s where the relationship actually lives.
Clay, this is the part I think support leaders need to operationalize next.
If AI handles the clean, repeatable work, the human queue becomes the judgment queue.
That changes how we should measure success.
Deflection alone is too clean of a number, which makes it dangerous, because humans apparently see a dashboard and forget reality exists.
I’d want to pair it with:
• delayed escalation rate
• repeat contact after AI resolution
• reopened tickets after AI handling
• handoff quality score
• agent readiness on AI-failed scenarios
The real question is not “how much did AI resolve?”
It is: “Did AI reduce work, or did it move harder work later?”
That distinction matters. Because if the agent only sees the angry, weird, risky 20%, then training, QA, and workforce planning need to be redesigned around that reality.
This piece nails the risk. The next layer is building the operating model around it.